Semantic correspondence made tremendous progress through the recent advancements of large vision models (LVM). While these LVMs have been shown to reliably capture local semantics, the same can currently not be said for capturing global geometric relationships between semantic object regions. This problem leads to unreliable performance for semantic correspondence between images with extreme view variation. In this work, we aim to leverage monocular depth estimates to capture these geometric relationships for more robust and data-efficient semantic correspondence. First, we introduce a simple but effective method to build 3D object-class representations from monocular depth estimates and LVM features using a sparsely annotated image correspondence dataset. Second, we formulate an alignment energy that can be minimized using gradient descent to obtain an alignment between the 3D object-class representation and the object-class instance in the input RGB-image. Our method achieves state-of-the-art matching accuracy in multiple categories on the challenging SPair-71k dataset, increasing the PCK@0.1 score by more than 10 points on three categories and overall by 3.3 points from 85.6% to 88.9%. Additional resources and code are available at dub.sh/semalign3d.
We build 3D object class representations for each category in the SPair-71k datasets. SPair-71k is a popular dataset for semantic matching which includes 18 categories, each containing 100 images (55 train images) with keypoint annotations (eg. "left wing end" is a keypoint).
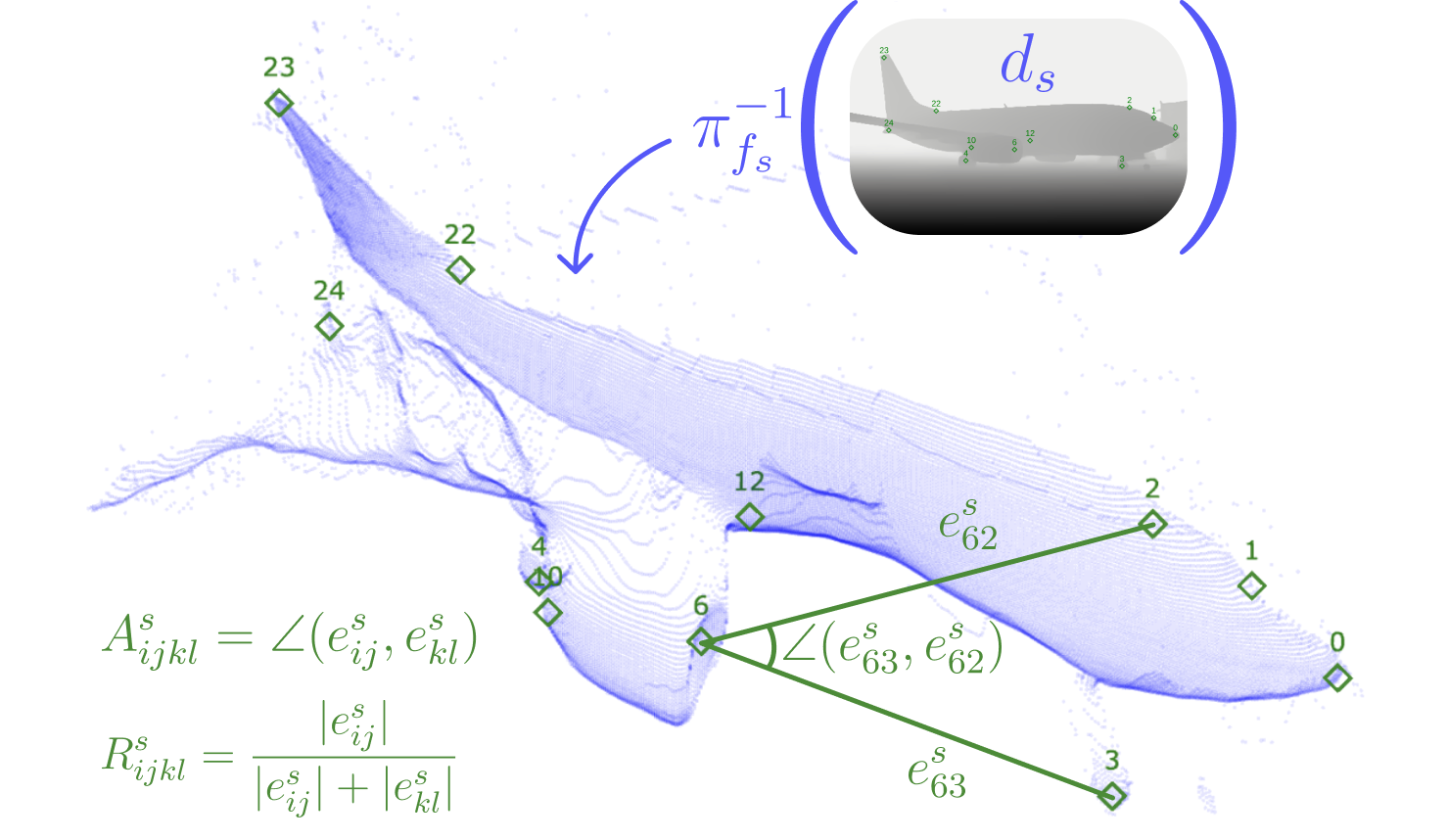
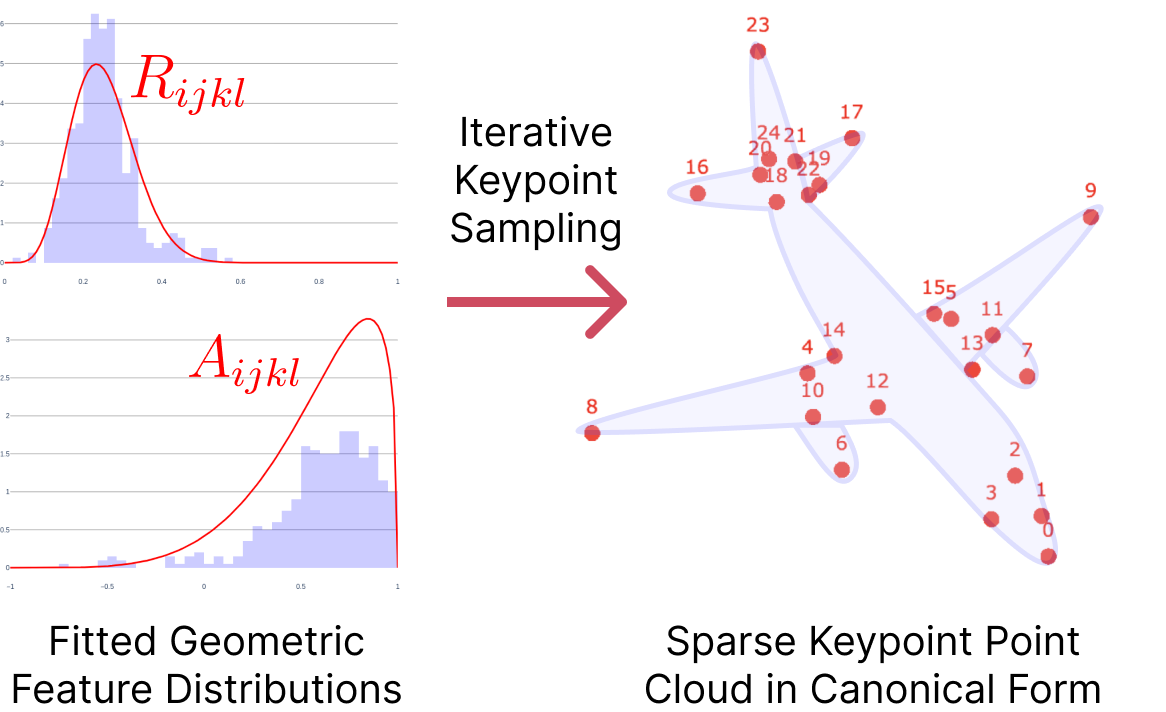
Representations are obtained in five steps:
Let's recap the task: Given two RGB input images, \(\text{img}_1\) and \(\text{img}_2\), and query points in \(\text{img}_1\), we want to find the corresponding semantic matches in \(\text{img}_2\). Previous methods like GeoAware mainly rely on semantic image features computed via fine-tuned DinoV2 model + Window SoftMax for matching. In contrast, our method first aligns 3D object class representations with object instances in input images. Then, we combine semantic + spatial likelihood for matching.
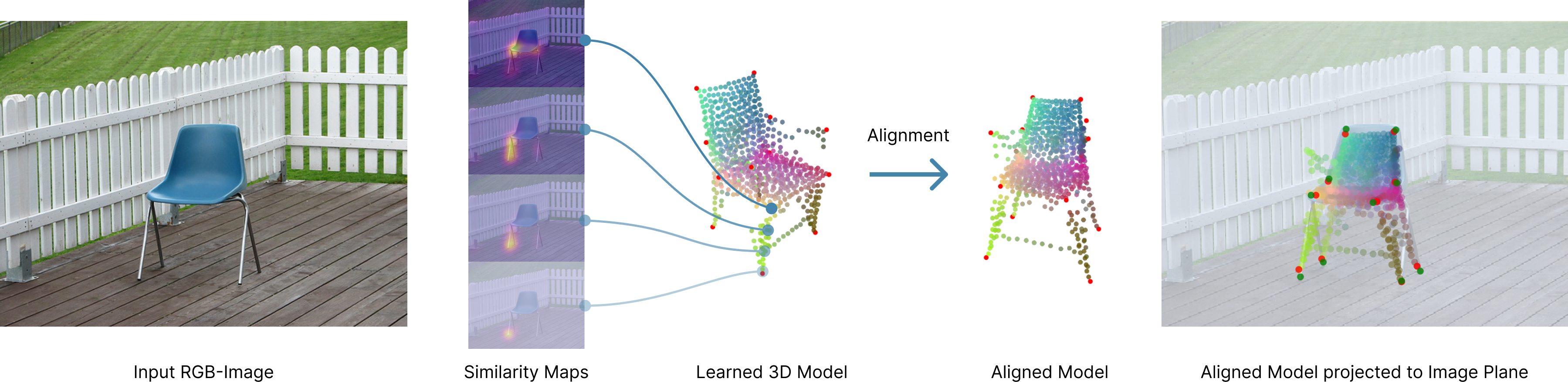
The alignment loss function consists of four terms:
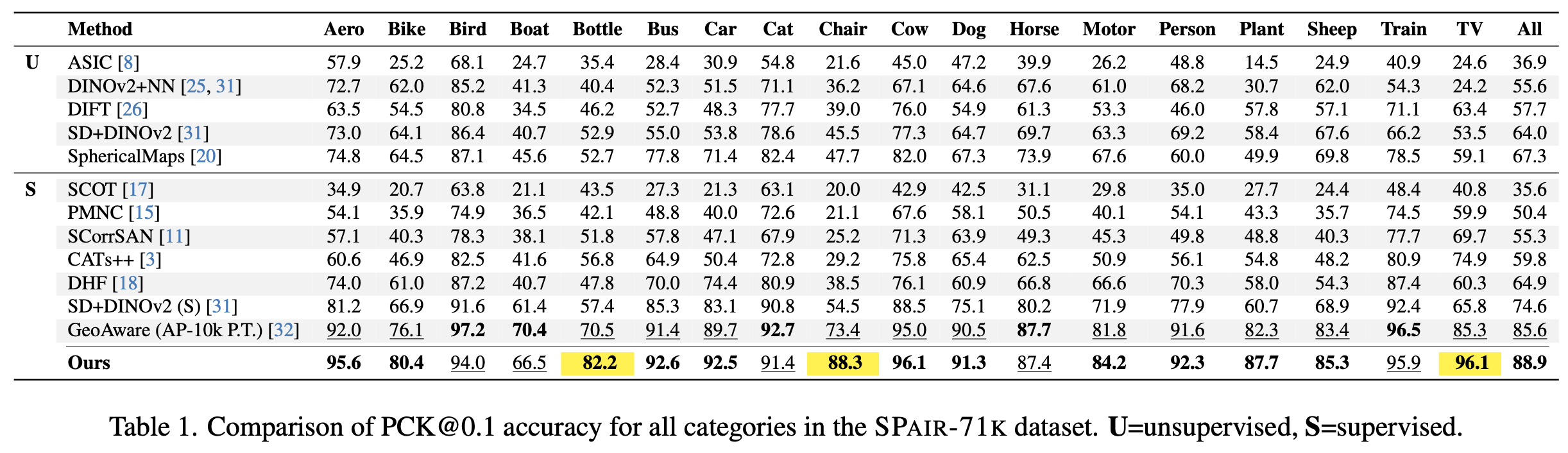
We report the Percentage of Correct Keypoints (PCK) on the challenging SPair-71k dataset. Our method shows significant increased matching accuracy, in particular on rigid objects. Please consult our paper for additional experiments, metrics, and datasets.

Please join my personal Discuna community at app.discuna.com/invite/krispinwandel to ask questions instead of writing me an email so that others can learn from your questions as well.
@misc{2025_semalign3d,
title={SemAlign3D: Semantic Correspondence between RGB-Images through Aligning 3D Object-Class Representations},
author={Krispin Wandel and Hesheng Wang},
year={2025},
eprint={2503.22462},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.22462},
}
